Enterprise users are increasingly interested in implementing complex video analytics use cases that provide business value beyond typical applications. These involve multi-stage models for object detection and image classification with custom trained models that are integrated to solve business problems. Some examples include:
Segment
Use case
Deep learning tasks
Retail
Cashier-less store
Pose detection, object detection, classification, etc.
Manufacturing
Worker safety
Pose detection, object detection, classification, etc.
Deep learning models for object detection and image classification
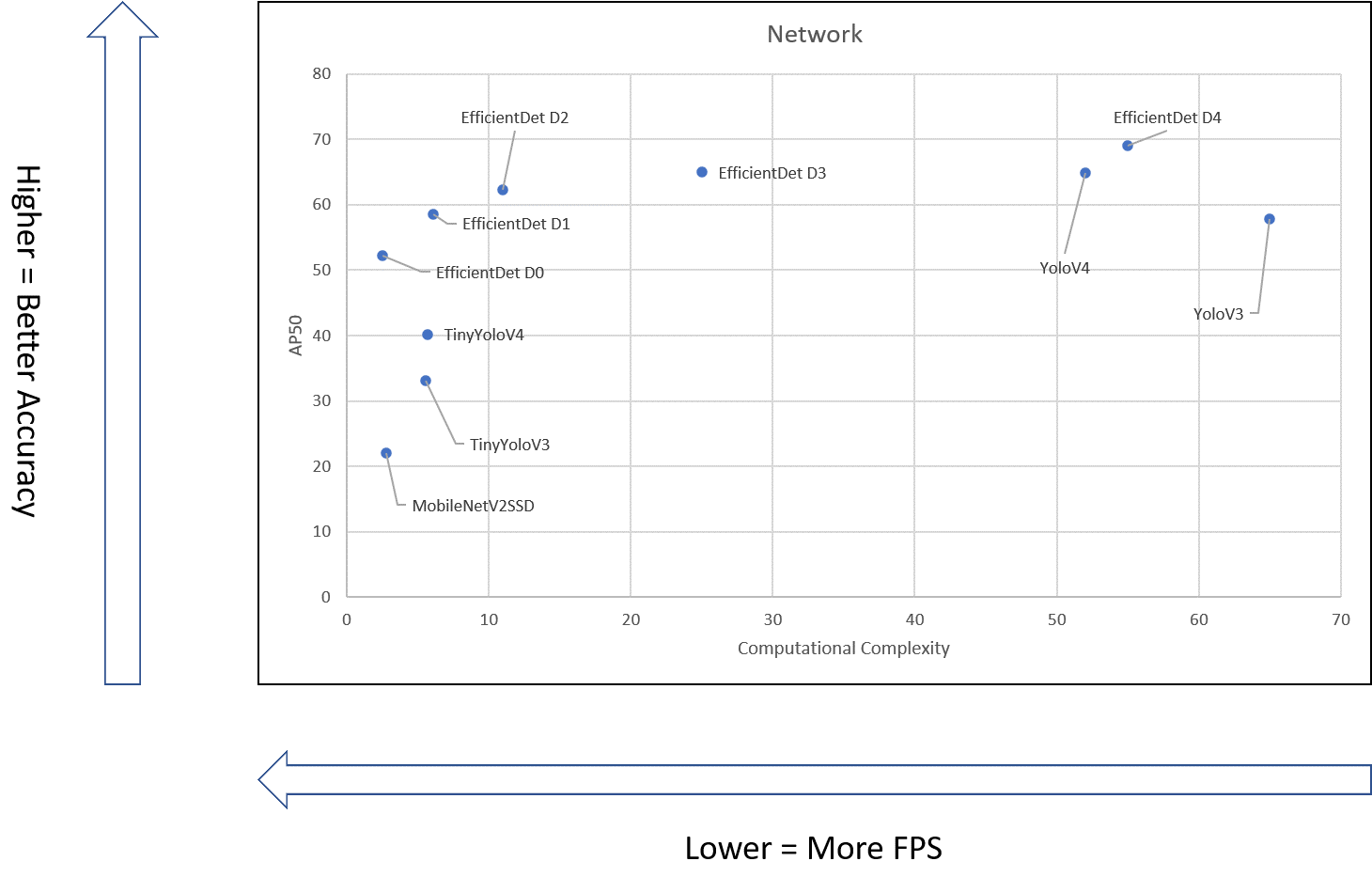
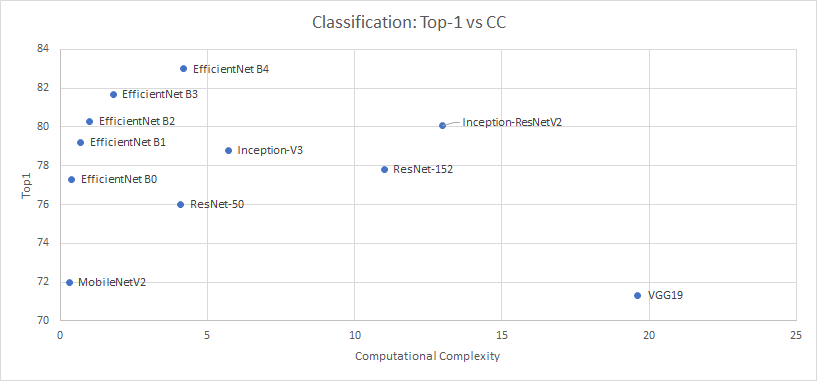
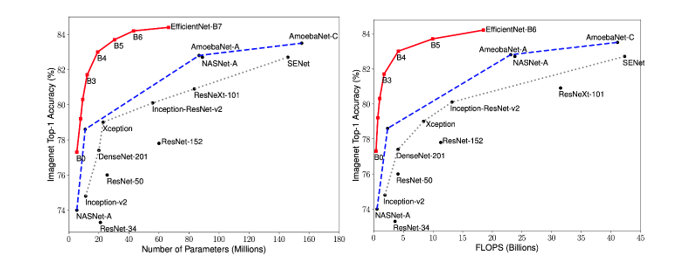
The two graphs below show the accuracy vs. complexity of implementing the newer models for object detection (EfficientDet) and image classification (EfficientNet) vs. the traditional models.
GPU implementation
The throughput of YOLOv3/v4 and EfficientDet object detection models on Nvidia V100 is shown below. These newer models use depth-wise convolutions of some form that do not map well to GPUs. YOLOv3/v4 operate at approximately 100 fps on the V100, while EfficientDet can only achieve approximately 50 fps (though it has much lower complexity).
For image classification, ResNet models can run at approximately 1000 fps on a T4, but EfficientNet models that can deliver higher Top1 accuracy at lower complexity run at approximately 50 fps for batch = 1 on a T4.
FPGA implementation
Unlike the GPUs, we are able to map these newer models to the FPGA, delivering very high throughput. The wider sparse networks map very well to the FPGA using DLE’s pipeline architecture. Below are the current and projected performance numbers for these networks on FPGAs.
Object detection models (fps)
Ver 1 (Sept)
Ver 2 (Oct)
Ver 3 (Nov)
MobileNetv2 SSD
1000
1300
2000
TinyYOLOv3
350
600
1000
TinyYOLOv4
370
650
1100
YOLOv3
90
110
200
YOLOv4
100
125
250
EfficientDet D0
250
600
900
Image classification models (fps)
Ver 1 (Sept)
Ver 2 (Oct)
Ver 3 (Nov)
MobileNetv2
1000
1400
2200
ResNet50
550
850
1200
EfficientNet B0
900
1200
1600
We are mapping these models to DLE in phases:
Ver 1 is the baseline performance by running the model through the current version of DLE compiler using on-chip (BRAM and URAM) and DDR memory for weights and the DSPs mapped for single multiplication.
Ver 2 is with DSP multiplier optimization. This will allow us to double the number of multiplications supported by sharing a DSP for two sets of operations. This should enable further scaling and more throughput.
Ver 3 is with dual clock optimization and involves running the DSPs at 400+ MHz and the core logic at half that speed. This will allow increasing throughput further.
Megh’s DLE implemented on FPGAs delivers more than 10x the performance for models like EfficicentNet and EfficientDet compared to GPUs. This higher throughput coupled with the flexibility and scalability of Megh’s Video Analytics Solution offers a very compelling value proposition for implementing complex video analytics use cases.
Learn more about Megh’s DLE and other products at megh.com.