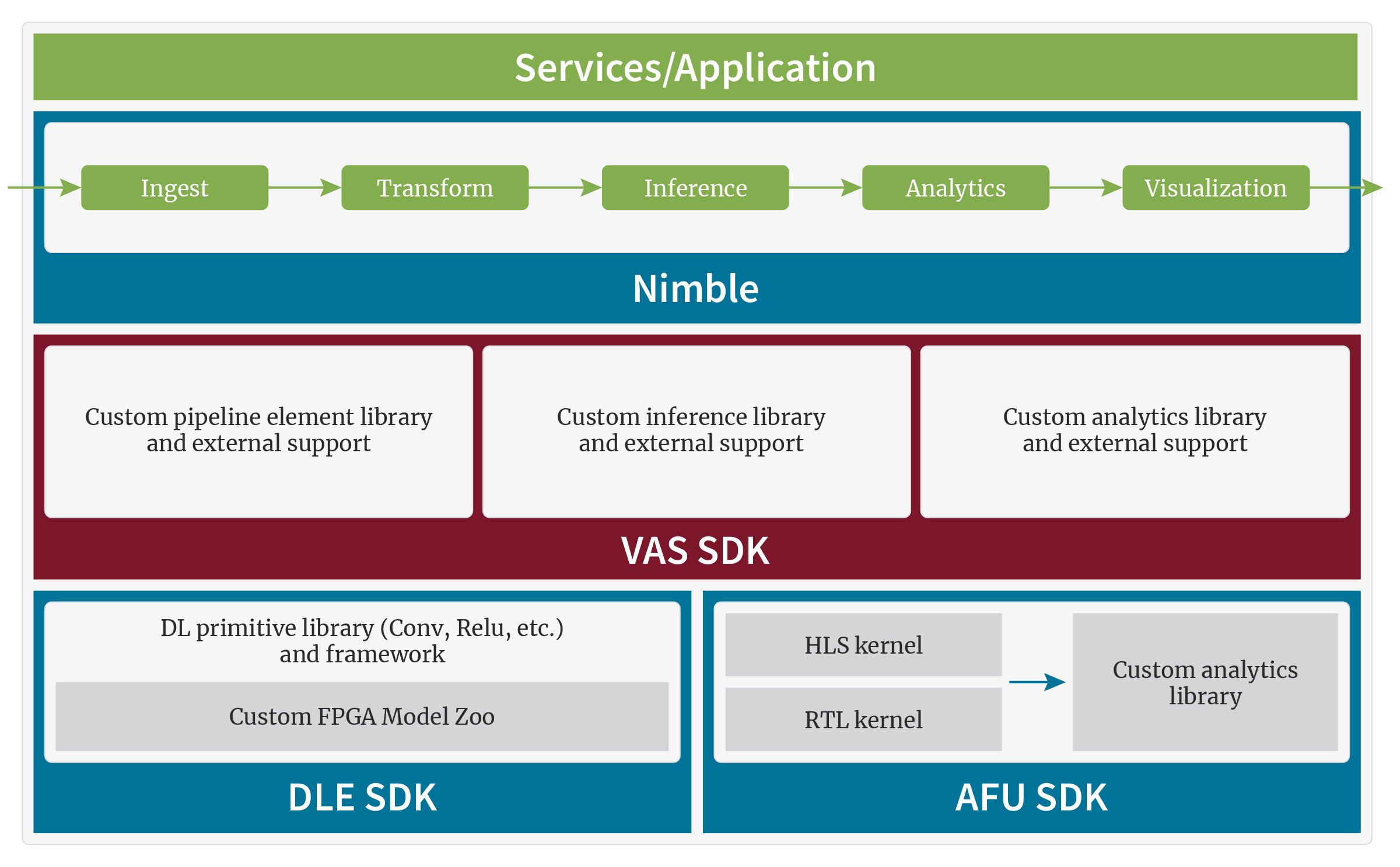
Megh’s fully customizable, cross-platform Video Analytics Solution (VAS) is available as the VAS SDK toolkit and VAS Suite of products. VAS SDK is targeted for enterprises, system integrators (SI), OEMs, and developers, enabling full control to optimize video analytics pipelines and integrate highly customizable AI into applications.
VAS SDK is one member of Megh’s family of SDKs:
VAS SDK: Configure real-time video analytics pipelines across CPU, GPU, and FPGA platforms for deployment from edge to cloud.
DLE SDK: Train, build, and deploy custom Pytorch and TF-Lite models on FPGAs for inferencing.
AFU SDK: Develop custom FPGA accelerator function units (AFUs) for analytics using RTL/HLS for deployment on scale-out FPGA platforms.
Click to enlarge
This blog post discusses how we implement, integrate, and deploy custom AI models and custom pipeline elements with VAS SDK.
VAS SDK exposes simple, well defined and documented APIs and interfaces to achieve these key features:
Easy integration of custom algorithms and analytics pipeline stages into the open-source VAS Pipeline Elements and Analytics Library
Seamless integration of custom deep learning models into the open-source VAS Inference Library via a flexible deep learning backend infrastructure
Quick and easy deployment with the newly integrated custom models and pipeline stages enabled by static configuration files or RESTful APIs
Support for standalone inference-as-a-service deployments
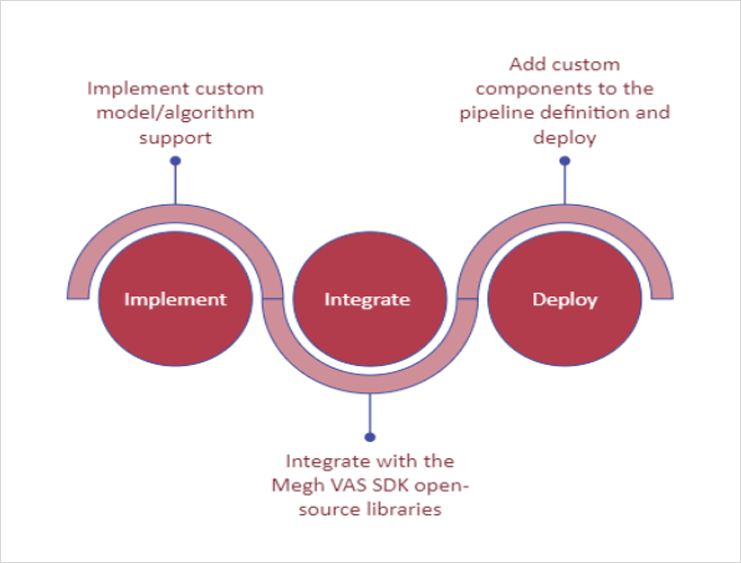
Megh VAS SDK speeds up time-to-market by bringing custom video analytics solutions from proof-of-concept to stable production deployments. A simple three-stage process to achieve this is illustrated below.
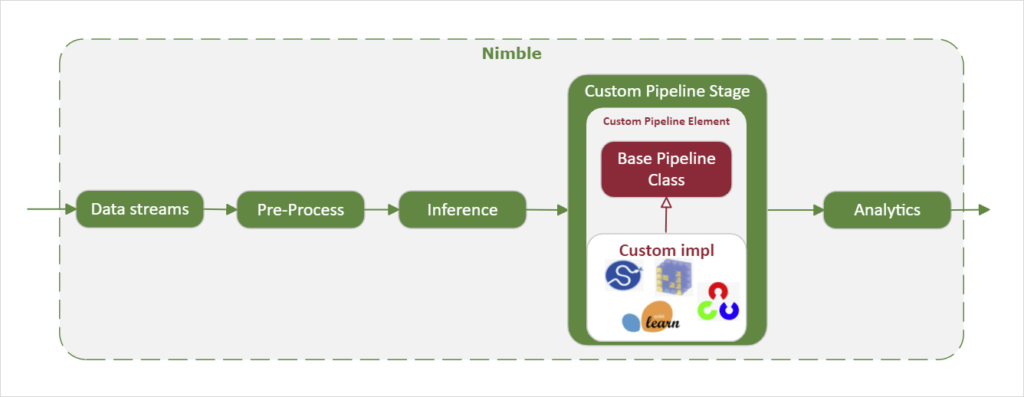
1. Add custom pipeline
Implement
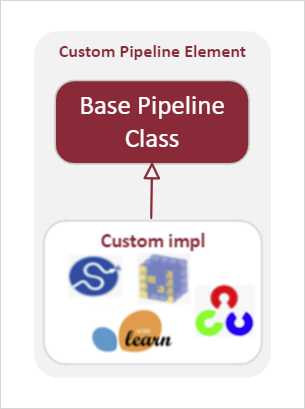
First, the custom algorithm is implemented using Python libraries such as SciPy, Scikit-Learn, NumPy, OpenCV, etc. The user-created pipeline element is inherited from the base pipeline element class, providing telemetry and quality of service features for monitoring performance and health of the workload.
Integrate
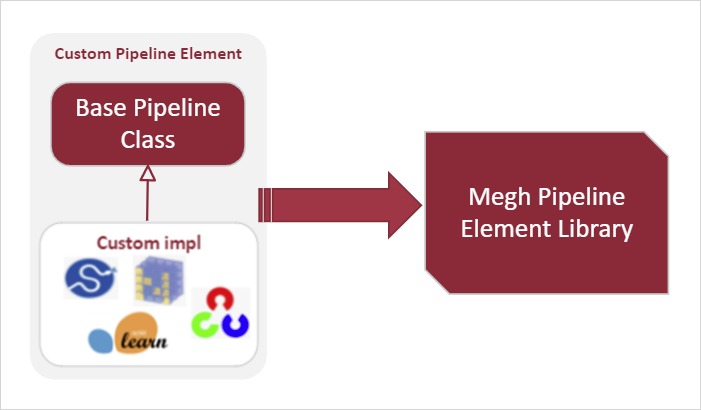
Next, the custom pipeline element is integrated into the Megh pipeline element library. This enables discovery and deployment of the user-created pipeline element either via static configuration files or the RESTful APIs.
Deploy
Finally, the custom pipeline element is added into the end-user pipeline definition and deployed, enabling the workload.
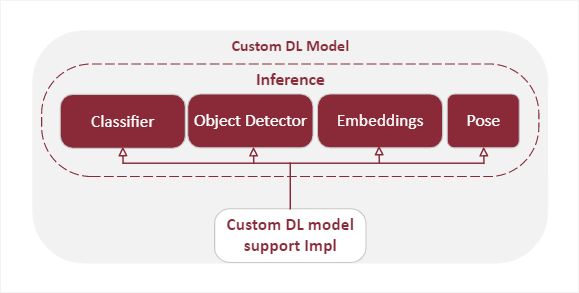
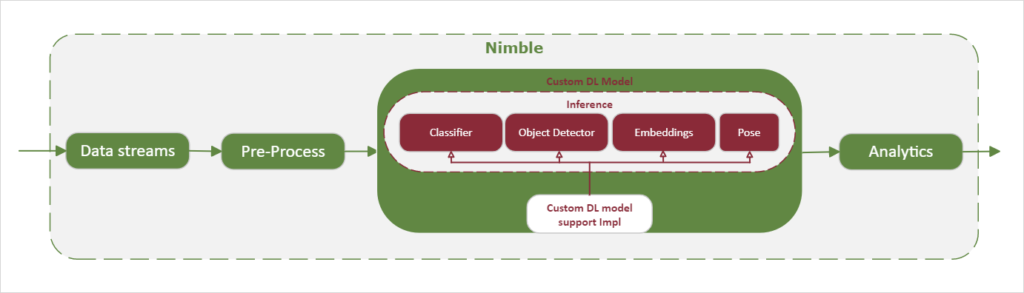
2. Add custom deep learning model
Addition of a deep-learning model follows a similar structure as a custom analytics stage.
Implement
First, the user creates a model wrapper that inherits from a base inference class type. Image classification, object detection, pose detection, and feature extraction (embeddings) are the currently supported types, with more to come. Additionally, preprocessing and post-processing functions need to be implemented by the user, depending on requirements of the model.
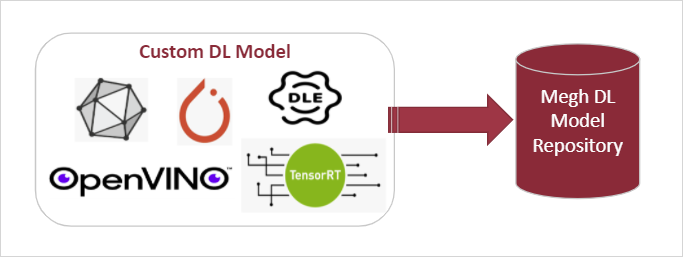
Integrate
Leveraging our flexible backend architecture, the user has many options for a deep-learning framework to integrate their custom model into VAS. Importantly, if the model definition is consistent across the different frameworks then the same model wrapper created in the previous step can be reused. An example of this is to use the PyTorch or ONNX backend for quick integration and accuracy testing. When the model has stabilized, it can be converted to OpenVINO, TensorRT, or Megh DLE for accelerated inference across multiple platforms, all using the same model wrapper. These model wrappers are then discovered by VAS SDK and can be deployed either via static configuration files or the RESTful API.
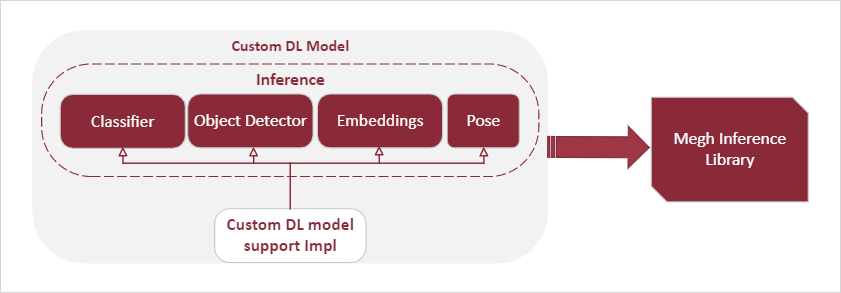
Deploy
Finally, the custom model is added to the end-user pipeline definition and deployed, enabling the workload. Importantly, if the model is available via the different backends, the same pipeline definition can be used across CPUs, GPUs, or FPGAs.
VAS SDK can be deployed as a standalone service that only performs deep-learning inferencing (inference-as-a-service). This flexibility of slicing the pipeline at different stages facilitates disaggregated cluster deployments. Here, we illustrate an inference pipeline ingesting decoded video frames from an upstream micro-service through a ZMQ interface.
The following video illustrates a Megh VAS pipeline deployed with a custom QR code scanner stage. The QR code scanner pipeline element was quickly integrated by following the simple three-stage process of integrating user-defined custom pipeline elements into VAS SDK. The custom pipeline stage integrated seamlessly with the PPE-detection pipeline sample provided with VAS.
Megh’s VAS SDK enables enterprises, system integrators (SI), OEMs, and developers to gain full control, optimize their video analytics pipelines, and easily integrate highly customizable AI into their applications.